

The Covid-19 pandemic is still quite uncontrolled in the US.
In this post, we’re going to walk through an analysis that was conducted by the UCHealth data science team looking at “leading indicators” that could help us to plan for a coming spike in COVID-19 inpatient hospitalizations before we actually see an influx of bed demand.
Perhaps, if we start to see more patients reporting a cough, fever, chills, and other flu symptoms, we would expect that this may indicate a growing spread of COVID-19. However, can we actually use the prevalence of these symptoms to predict how many ICU beds will be needed for COVID-19? What about less common symptoms of COVID-19, such as loss of smell or taste, that have been shown to be more predictive of COVID-19 infection?
While this may sound like a relatively straightforward question, there are a number of confounding effects that make it difficult. The above graphic shows the number of patients making an outpatient or virtual office visit due to a fever. As expected, there is a general downward trend as the seasonal influenza season subsides. However, there also appears to be a “spike” in reports of fever in early March in our Northern Colorado geography (orange line). Could this spike be quantified for future predictions?
Defining a “symptom” in our Epic electronic health system is complex. For example, symptoms can be documented as the “reason for visit”, but a medical assistant may or may not choose to report all symptoms as the visit reason. Besides “reason for visit”, our Epic team has developed a COVID-19 symptoms checklist that screens patients at check-in (completed by front desk staff). This list was expanded substantially in the midst of the epidemic based on new evidence (for example, loss of smell). The consequence is that we saw an increase in reporting of these symptoms in April, due to the new data fields, while our actual number of COVID-19 inpatient cases was declining. In short, there is a significant amount of noise to parse through before arriving at a prediction we can trust.
How did we go about identifying the signal from the noise? Knowing that there was no “right” answer, we tested different approaches. I’m going to focus here on the most recent modeling attempt that we have found to be most insightful. We started with the premise that the correlations between our independent variables (reported reason for visit, reported COVID-19 symptoms, and documentation of ICD-10 billing codes indicative of confirmed or potential COVID-19 infection) and our dependent variable (number of COVID-19 inpatient hospitalizations) would change over time due to trends in seasonal influenza and introduction of new codes/data elements in our EMR system. We therefore constructed separate linear regression models for the months of March (when the epidemic hit and we did not yet have IT system capabilities for tracking many symptoms), April (when COVID-19 cases hit their peak and then declined, accompanying a ramp-up in new IT system capabilities), and May (something of a “steady state” when seasonal influenza had passed and no major IT updates were made regarding COVID-19 symptoms or billing codes).
We wanted to test a large number of independent variables, and therefore chose to use a linear regression method known as LASSO regression instead of the traditional OLS modeling technique. LASSO regression introduces a regularization parameter that penalizes large coefficients in the model. Instead of optimizing to minimize prediction error, the model minimizes the below cost function:

- Y: Dependent variable
- X: Independent variable
- β: Regression coefficient
- λ: Regularization parameter
- n: Number of observations
- p: Number of independent variables in the model
In plain English: we reduced the complexity of the model and thus reduced the chance of spurious correlation or the influence of random “noise” in the data.
Our independent variables were reported outpatient symptoms and diagnoses in the seven days prior to the index date, and our dependent variable was the number of COVID-19 hospitalizations in the seven days after the index date. For example, on May 1 we fit the numbers of reported symptoms and documented ICD-10 codes from the prior 7 days (4/24-4/30) to the number of hospitalizations in the next 7 days (5/1 – 5/7). An astute reader will note that our modeling approach violates one of the tenets of linear regression modeling in that the observations are not mutually independent, but rather a time series. To mitigate this issue, as well as the small number of observations in a given month, we used a procedure drawing bootstrapped samples from each month 100 times, and for each sample, using a 5-fold cross validation process to determine the optimal regularization parameter, fit a LASSO regression model. A bootstrap sample is a random sample of the same size as your original data drawn at random with replacement from the original data, so in some samples data points for 5/1, 5/2, and 5/3 will all be included, some may only include 5/1, and some may include none of those data points.
Once again giving a simple English translation for those less interested in the modeling approach: we introduced some randomness to our data to give ourselves better confidence in our estimates of the linear correlation between each variable and our outcome of number of future COVID-19 hospitalizations.
The below table summarizes, by month, the average correlation coefficient from all of the LASSO regression models fit to bootstrapped samples of data from that month, sorted in decreasing order by the value in May. Please interpret the nomenclature as follows:
- reason_visit: Indicates the variable is the reported reason for visit in an outpatient or virtual encounter
- symptom: Indicates the variable is one of the COVID-19 symptoms selected from a checklist by clinicians at the beginning of outpatient/virtual encounters
- icd: Indicates the variable is documentation of an ICD-10 code referencing confirmed or suspected cases of COVID-19
| Variable Name | March Coefficient | April Coefficient | May Coefficient |
| reason_visit_COUGH | -9.80977 | 1.995882 | 7.786421 |
| reason_visit_FEVER | -0.73825 | 0.487601 | 2.66054 |
| reason_visit_CORONAVIRUS CONCERN | 1.167884 | -0.16012 | 2.399324 |
| symptom_Fever | -0.52706 | 0.553718 | 0.626149 |
| reason_visit_SHORTNESS OF BREATH | 0.716685 | 0 | 0.599447 |
| icd_B34.2 | 3.006547 | 0.297723 | 0.311514 |
| symptom_Vomiting | 0 | -1E-15 | 0.22527 |
| symptom_Diarrhea | 0 | 0 | 0.179083 |
| symptom_Shortness of breath | 0.241053 | -0.01326 | 0.134918 |
| symptom_Cough | 2.25537 | 0.100087 | 0.042621 |
| icd_R68.89 | -0.42723 | 0.790427 | 0.020276 |
| icd_Z20.828 | 0.254416 | -0.10133 | 0.002899 |
| symptom_Red eye | 0 | 0 | 0 |
| symptom_Loss of smell | 0 | 0 | 0 |
| symptom_Rash | 0 | 0 | 0 |
| symptom_Joint pain | 0 | 0 | 0 |
| symptom_Sore throat | 0 | 0 | 0 |
| symptom_Bruising or bleeding | 0 | 0 | 0 |
| symptom_Weakness | 0 | 0 | 0 |
| symptom_Abdominal pain | 0 | 0 | 0 |
| symptom_Loss of taste | 0 | 0 | 0 |
| symptom_Muscle pain | 0 | 0 | -0.10438 |
| symptom_Chills | 0 | 0 | -0.15124 |
| symptom_Severe headache | 0 | -0.53023 | -0.16017 |
| icd_U07.1 | 0.253596 | -3.47782 | -0.24094 |
The strongest positive correlation with future COVID-19 hospitalizations in the month of May was “cough” as the reason for visit. At first, the trend in this correlation over time seems counterintuitive. Why would we see such a strong negative correlation in the month of March but a strong positive correlation in the month of May? Well, a reasonable hypothesis has to do with the ramp-up in COVID-19 testing coinciding with the end of the 2019-2020 seasonal flu. In March, we saw an overall decline in patients seeking outpatient care for a cough, likely due to both the end of seasonal flu and social distancing keeping patients from seeking treatment at medical facilities, while we simultaneously initiated widespread COVID-19 testing at our inpatient facilities and saw a rapid rise in confirmed cases. In May, by comparison, there was no noise from the seasonal flu influenza and no significant backlog in testing to ramp up.
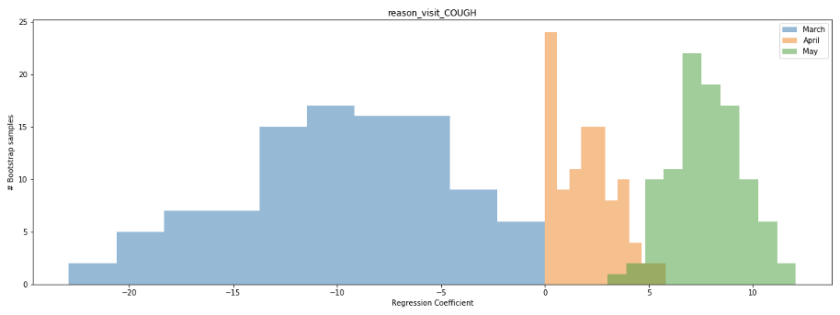
We can also look at the distribution of the regression coefficient for the cough variable in our bootstrapped samples to better establish our confidence in the value. The below histogram shows the distribution of the coefficient across all 100 bootstrapped samples for the months of March (blue), April (orange), and May (green). Notice that for a large number of samples from March and April, the coefficient is near 0, while for the month of May it ranges consistently between 5-10. What does this mean? It means that a few data points in March and April are likely having a disproportional impact on the estimate of the linear correlation, while the correlation in May is more consistent regardless of which dates are sampled.
Examining the scatterplot for the month of May, we see that this linear correlation does appear quite consistent across the time period.

After all of this analysis, what are our big takeaways? Can we take our regression model for the month of May and start using it to predict bed demand? Unfortunately, this would be unwise. One month of data is too limited a timeframe for us to be confident in our model. While we see a significant correlation between patients seeking treatment for a cough and inpatient COVID-19 hospitalizations in the month of May, both variables declined over the majority of the timeframe. We would feel significantly more confident in our model if we observed a spike in inpatient hospitalizations preceded by a large number of patients reporting in outpatient settings with a cough, as opposed to the continuous decline. Hopefully, this never happens, but we believe a second wave of COVID-19 infections is very probable by at least next Fall or Winter. Our plan is to continue to update our model with new data, potentially including new data sources such as patient engagement with our Patient Line call center resources or Livi chatbot feature, through the next wave of infections and observe performance before deploying to assist in the management of hospital resources.

–Brendan Drew, UCHealth data scientist